How does Spectre work?
This article is my submission for the Handmade Network's 2024 Learning Jam. As such, it is the from the perspective of a recent learner, NOT the perspective of an expert on CPUs or CPU vulnerabilities. I have attempted to verify the article's contents as well as I can, but please do not consider it an authoritative source.
Also, due to time constraints, this article does not work well on mobile. Sorry!
Spectre is a CPU vulnerability published in 2017. Or rather, it's a class of vulnerabilities—a collection of exploits inherent to the design of modern CPUs.
Spectre leverages a feature of the CPU called speculative execution to exploit otherwise-correct programs and extract information that should otherwise be secret. Spectre is subtle, but also very simple, and in this short article I hope to give you an intuitive sense of how Spectre works and what can (or can't) be done to mitigate it.
The subject of our investigation is this innocuous-looking snippet of code from the Spectre paper. By the end, it should hopefully be clear how this seemingly correct code can be exploited.
if (x < array1_size) {
y = array2[array1[x] * 4096];
}What is speculative execution?
Before covering speculative execution, we first have to discuss out-of-order execution. Let's start with a simpler code example:
arr[0] = arr[0] / 2;
arr[1] = arr[1] / 3;We would intuitively expect the following operations to happen in the order written, but the CPU may actually execute the instructions in a different order. The end result will still be exactly the same, but this reordering can achieve much greater performance! This is because accessing memory is slow—main memory is hundreds of times slower than comparisons or arithmetic. In addition, CPUs can execute multiple instructions in parallel, overlapping the work and finishing the entire process more quickly.
No reordering, no pipelining
arr[0] from memoryarr[0] / 2arr[0]arr[1] from memoryarr[1] / 3arr[1]Reordering / pipelining
arr[0] from memoryarr[1] from memoryarr[0] / 2arr[1] / 3arr[0]arr[1]However, conditionals present a problem. If the code contains an if statement, the CPU cannot know whether the if statement will be true or false. This creates a bottleneck where the CPU must fully compute the condition before it can proceed.
Or that would be true, if not for speculative execution. Rather than wait for a condition to be resolved, the CPU instead predicts (speculates) whether the condition will be true or false, and proceeds accordingly. If it guesses correctly, then it saves time. If it guesses incorrectly, then it discards the incorrect work and tries again, at a small penalty. In the following example, the CPU will predict that the condition is true, which may or may not be correct.
n = arr[i];
if (n % 2 == 0) {
arr[i] = n / 2;
} else {
arr[i] = n * 3 + 1;
}Correct prediction (n is even)
arr[i] from memoryn % 2n / 2n % 2 == 0n / 2Incorrect prediction (n is odd)
arr[i] from memoryn % 2n / 2n % 2 == 0n / 2n * 3 + 1n * 3 + 1Speculative execution is critical for out-of-order execution, and out-of-order execution is critical for performance. And as long as the CPU can perfectly roll back a bad speculation, there should be no problems!
...CPUs can perfectly roll back a bad speculation, right?
No they cannot
When a CPU rolls back work, it restores the contents of all the registers and discards any pending work. In theory, this should be completely invisible to the program—it should not be able to tell that the CPU did anything unusual. However, CPUs are real devices with real limits, speculative execution is real execution, and the effects of speculative execution can in practice be observed in clever ways.
For the simplest Spectre exploit, we will look at the effect of speculative execution on the cache. As mentioned, main memory is extremely slow, so CPUs have a cache for recently-accessed memory. This cache makes memory accesses hundreds of times faster, but it has an important property for Spectre:
On a bad speculation, the cache does not get rolled back.
Speculative loads are real loads that will cause main memory to be fetched and stored in the cache. This is nominally invisible to the program, but the whole point of the cache is to improve performance—and performance is observable.
Timing attacks!
Timing can tell you a surprising amount about a system. Consider the following interactive example, which simulates a simple login page.
Log in
Attempts
| username | response | timeline |
|---|---|---|
| alpha@example.com | ||
user = database.get(req.username)
if not user:
return "bad login"
if not checkPassword(user.password, req.password):
return "bad login"
return "success!"| username | password |
|---|---|
| alpha@example.com | hunter2 |
| bravo@example.com | dolphins |
| charlie@example.com | Password1! |
| ??? | ??? |
Notice that, despite the message "bad login", the timing of the response reveals whether the username exists in the system or not. When a user is not found in the database, it returns quickly, but when a user is found, it will also run an expensive password check. See if you can figure out the username of the hidden user in the database using this information.
This idea extends to many other systems. Generally, timing a system can tell you something about the work being done, even if you can't observe that work directly. So, it's now time to combine this idea with our knowledge of CPU caches and speculative execution.
Reading memory with only a timer
While it may be interesting that timing a system can reveal some insights about how it works, it's not clear how this can be used to actually do anything serious. However, it is actually possible to extract the contents of memory using nothing but a timer.
Suppose we have the following code:
char dereferenceAndLookup(char* p) {
return probeArray[*p];
}
This code will dereference a pointer, then use the value it finds to index into an array. Because accesses to memory are cached, this means that some element of probeArray will be in cache—specifically the index corresponding to *p.
This is now exploitable via a timing attack. Whichever index of probeArray loads fastest is the value of *p.
You can see this in the demo below. Choose an address to run the function with, then click on the elements of probeArray to see how quickly they load.
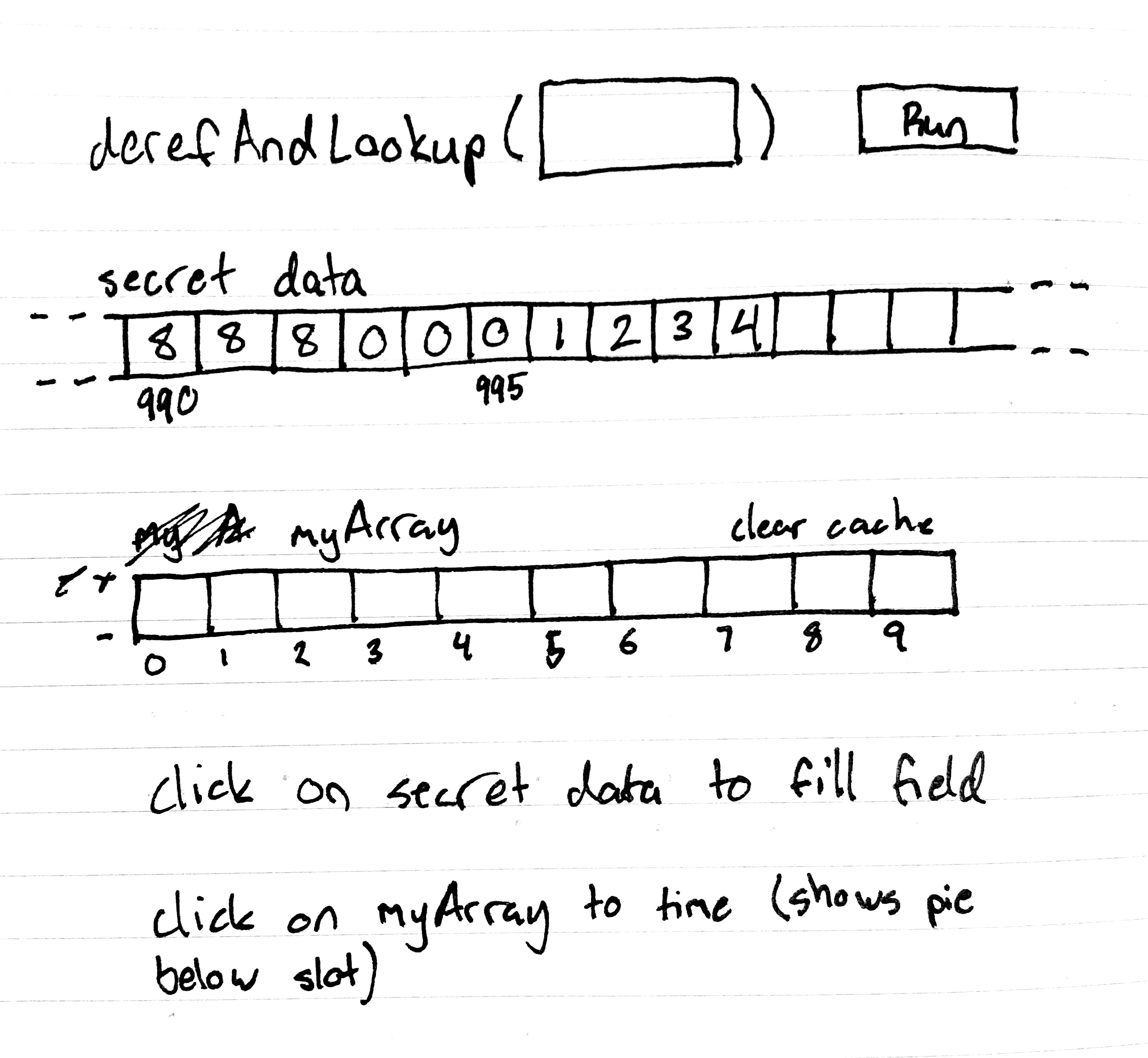
Note for pedants: yes, I know that CPUs do not cache individual integers. I will address this later, I promise.
Things are now more serious. The stage has been set for a proper Spectre exploit.
The (almost) real deal
The roadmap for our exploit is as follows:
- Make the CPU load from an address containing a secret byte
s - Make the CPU use
sto index an array - Find the fast element in the array to learn the value of
s
Step 1 might seem potentially difficult to achieve in languages without pointers. In JavaScript, for example, we can't just write int s = *(int*)(0xDA7A) to access a memory address directly. However, in nearly any language, we can simply use arrays to bypass this limitation.
In a sense, you can think of an array index as a relative pointer—an address relative to the start of the array. If we can determine the address of the array itself, we can use it to access whatever data we like. For example, if the array is at address 1000, and we would like to read memory address 1234, we can simply access array[234]. Or, we can just throw random indexes at the array and see what we find out of bounds.
Of course, well-written programs have bounds checks to ensure that you cannot read an array out of bounds. But speculative execution can bypass this limitation, as we saw before. The CPU can speculatively load the out-of-bounds data before it knows that it is out of bounds—and this will be reflected in the cache.
We can therefore modify our prior example to look like this:
char probeArray[255];
char exploitable(int i) {
if (0 <= i && i < arraySize) {
char secret = pointerishArray[i];
return probeArray[secret];
}
return -1;
}
If CPUs never ran code out of order, this code would be completely fine. Any out-of-bounds value for i would be handled correctly, and secret data would never be loaded. But this is not what actually happens.
Suppose we call exploitable with a malicious, out-of-bounds value for i. If the CPU speculates that the if statement will be true, it is assuming that i is in bounds and the data is safe to look up. It will then speculatively load pointerishArray[i], and speculatively load probeArray[secret] based on the result, making probeArray[secret] the fastest-loading element—even after the incorrect work is rolled back!
This technique is surprisingly portable. The previous examples have been in C, but the authors of the Spectre paper also demonstrated a JavaScript version of the exploit that could run in browsers. They were able to read data belonging to the browser process itself, simply by using JavaScript's Uint8Array. This means that a web page could potentially exploit the browser itself, just by running malicious JavaScript code that never actually triggers an error!
The fussy real-life details
The previous examples have simplified various aspects of the exploit. However, getting the exploit to work practically requires a few more tweaks that are worth addressing now.
First, CPUs do not actually cache individual integers. Instead they cache in larger units called cache lines, e.g. 128 bytes at a time. This means that loading a single element of probeArray will actually result in 128 values of probeArray being loaded into cache—not ideal for later determining the value of secret. This is why, in the Spectre paper, probeArray is much larger and secret is multiplied by 4096—this ensures that each access to probeArray will get its own cache line.
Second, running this exploit in practice requires you to force the CPU to speculate the way you want; specifically, you must train the CPU to predict that i is in bounds, and you must ensure that pointerishArray[i] is cached but arraySize is not. This ensures that the CPU will choose the correct path, and that it will speculate for a substantial amount of time while it waits for arraySize to load from memory. This can generally be achieved by deliberately reading from other memory addresses in such a way that arraySize is evicted from the cache.
Finally, probeArray must also be completely evicted from cache so that you can use the cache timings to determine the value of secret. This can be done the same way as for arraySize.
In conclusion
I wish I had more time to make interactive demos for this but oh well!!